📊 NZ Fuel & Food Price Correlation Pipeline
🚀 Project Overview
This project is a Data Engineering Pipeline built in Databricks to analyze the economic relationship between gasoline price fluctuations and the Food Price Index (FPI) in New Zealand.
The goal was to determine if spikes in fuel (specifically Diesel and Regular Petrol) directly correlate with rising food costs, and to identify any "time-lags" in this relationship.
🏗️ Architecture: The Medallion Approach
The pipeline follows the Medallion Architecture to ensure data quality and scalability:
Bronze Layer: Raw ingestion of Stats NZ and Fuel Price CSV files into Delta tables.
Silver Layer: * Data cleaning and type casting.
Feature Engineering: Created a custom dim_date table using the Python holidays library to flag New Zealand public holidays.
Aggregation: Downsampled daily fuel prices to a monthly mean to match the Food Price Index grain.
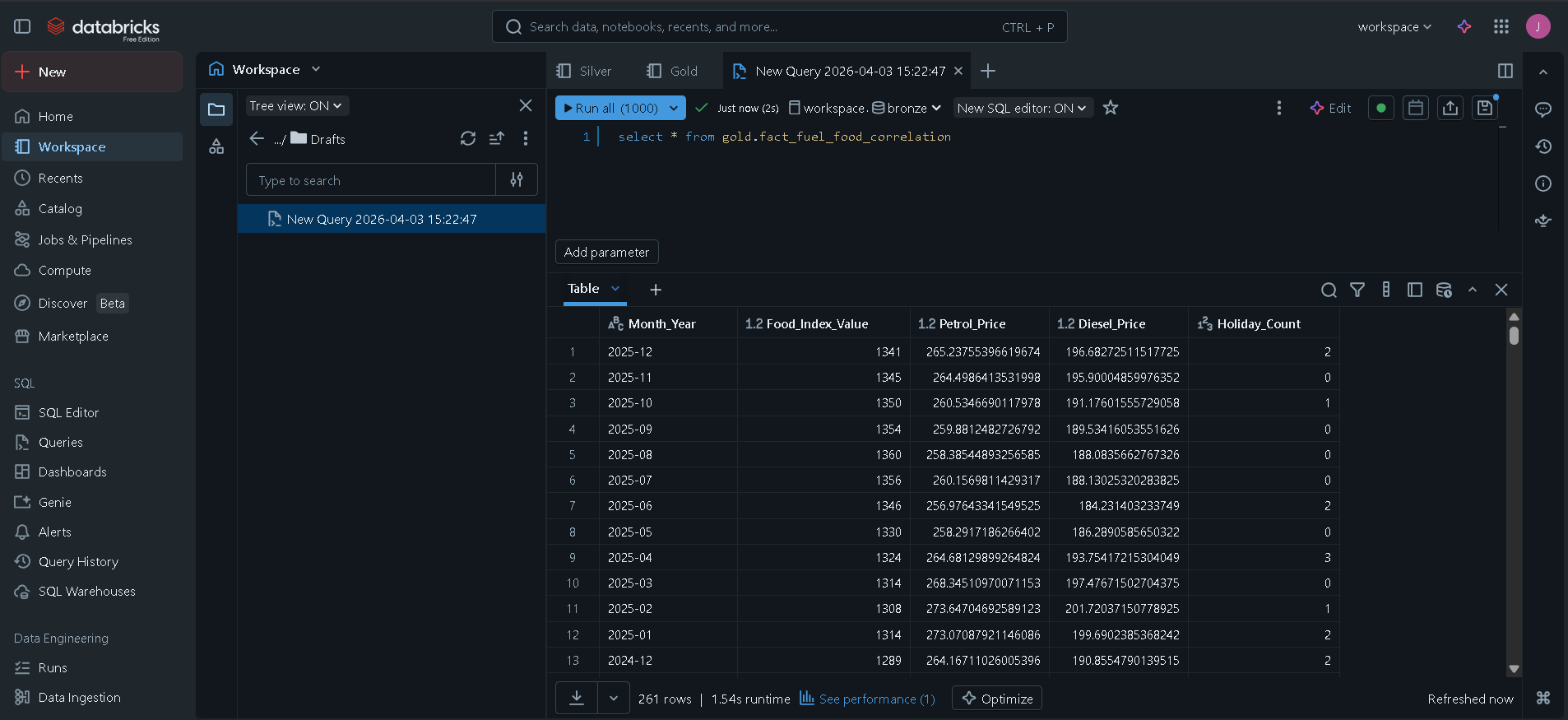
Gold Layer: * Implemented a Star Schema design.
Created a fact_fuel_food_correlation table by joining processed fuel, food, and date dimension data.
🛠️ Tech Stack
Platform: Databricks (Community Edition)
Language: PySpark (Python) and Spark SQL
Storage: Delta Lake
Orchestration: Logic designed for integration with Airflow/Databricks Workflows
Libraries: pandas, pyspark.sql.functions, holidays
📈 Key Features & Logic
Movable Holiday Logic: Automated detection of NZ-specific holidays (like Matariki and Easter) using the holidays library to account for seasonal price anomalies.
Data Normalization: Transformed the "1960M01" date format into standard SQL timestamps for seamless joining.
Business Intelligence Ready: The Gold layer is optimized for PowerBI/Tableau, pivoting fuel types into individual columns for immediate correlation analysis.
📂 Repository Structure
Bronze/: Notebooks for raw data ingestion.
Silver/: Transformation logic and Dimension table creation.
Gold/: Final Star Schema modeling and join logic.
SourceData/: Sample CSV datasets used in the pipeline.